페이스북은 그래프 검색을 어떻게 구현했을까?
최근 검색 분야의 화두를 꼽으라면 역시 페이스북 그래프 검색을 빼놓을 수 없다. 지인의 SNS에서 그래프 검색의 내부를 살짝 엿볼 수 있는 글을 접했다. 흥미로운 부분만 몇 가지 적어본다.
Query Suggestion
대부분의 검색 서비스와 마찬가지로 페이스북도 입력창에 “Sri”라고 입력하면 Sri로 시작하는 단어가 자동으로 제안된다. 그런데 “people who live in Sri”의 경우에는 Sri가 아마도 장소를 가리킬 것이다. 이 “상식”을 자동으로 판단해서 “Sriram Sankar”라는 사람 이름 대신 “Sri Lanka”라는 도시 이름이 나올 수 있도록 자연어 처리 기술을 이용한다.
Result Set Scoring
일반적으로 검색은 문서나 사진 같은 개체(Entity) 단위로 이루어진다. 질의어에 대해서 각 개체의 점수를 계산하고, 이 점수에 따라서 검색 순위를 결정한다. 이 방식의 문제는 -결과에서 중복을 제거하더라도- 사실상 동일한 개체만 상위에 노출될 수 있다는 점이다. 원글에서 예로 든 것처럼 “photos of Facebook employees”의 결과에 마크 주커버그의 사진만 잔뜩 나오면 사용자 만족도는 떨어질 것 같지 않은가? 이를 방지하기 위해 그래프 검색은 개체 단위 뿐만 아니라 검색 결과 집합(Result Set) 단위의 필터링을 통해 가장 흥미로운(Interesting) 부분집합을 뽑아낸다.
이 Result Set Scoring에 대한 설명이 완전 투명하지는 않지만, “nearby” 검색의 예로부터 대충 감은 잡을 수 있다. 개체의 점수를 계산하는 각기 다른 함수를 두고, 가령 인기도/나와의 소셜 관련도/물리적 거리를 중시하는 3개의 함수로 각각 점수를 계산한 뒤, 최종 결과에서는 이 세 함수로부터 점수 높은 것을 따로 뽑아서 섞는 방식으로 보인다. (다양화 문제는 검색이나 추천시스템에서 최근에 활발한 연구 주제 중 하나이고, 찾아보면 논문도 많다.)
Graph Search
그래프 검색만의 특징인 “restaurants liked by Facebook employees” 같은 질의는 어떻게 처리할까? 읽어본 바로는 뭔가 특별하고 감탄을 자아내는 모델은 없다. 대신, 직관적이고 합리적인 구현이 있다. 사용자가 입력한 이 자연어 쿼리는 기계가 해석할 수 있도록 아래와 같은 문장으로 바뀐다.
273819889375819/places/20531316728/employees/places-liked/intersect
여기서 273819889375819은 장소의 카테고리 중 하나인 음식점(restaurant)의 식별자이고, 20531316728는 회사 Facebook의 식별자이다. 이어서, 이 문장이 가리키는 결과를 얻기 위한 검색(+조인Join)이 순차적으로 진행된다.
- (term employee:20531316728): 페이스북 직원의 리스트를 얻는다.
- (and place-kind:273819889375819 (or liked-by:fbid1 liked-by:fbid2 … liked- by:fbidn)): 타입이 레스토랑이고, 위의 리스트가 좋아한 개체를 찾는다.
이 작업이 원활하게 이루어지기 위해서는 각 개체 타입마다 효율적으로 색인되어 있어야 할 것이다.
또 다른 그래프 검색의 특징인, 이름이 mark인 사람 찾기를 보자. 아래와 같은 친구 네트워크 상에서 Christna와 Sandhya가 mark를 검색했을 때, 검색어는 같더라도 둘에게 각기 다른 사람을 찾아주어야 한다.
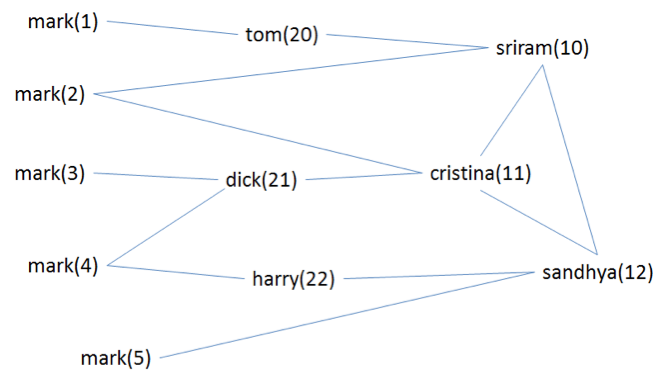
이를 위해서 페이스북은 그냥 단순히 친구 관계를 색인해두고 다음과 같이 검색한다.
- Christna: (and mark (or friend:11 friend:10 friend:12 friend:21))
- Sandhya: (and mark (or friend:12 friend:10 friend:11 friend:22))
해석하자면, (이름이 mark)이고 “그리고” (검색자의 친구이거나 혹은 친구의 친구)인 사람을 찾으라는 문장이다. 그래프 구조를 분석해서 두 사람 간의 거리를 멋지게 계산해서 최적의 후보를 찾아주는 기능은 아직은 없어 보인다. 그렇다면 친구가 아닌 유명인 mark를 찾는 경우는 어떨까? 내 친구 네트워크 밖의 사람은 못 찾는 것 아닌가? 이 문제를 해결하기 위해서 그래프 검색은 weak AND, strong OR이라는 연산자를 도입했다. 집합 시간에 배운 AND와 OR을 적용하되 너무 엄격하지는 말라는 것인데, 퍼지셋을 연상시킨다. 아무튼 이 연산자를 쓰면 위의 검색 쿼리는 아래와 같이 바뀐다.
(weak-and mark (or friend:11 friend:10 friend:12 friend:21)[0.7])
이름이 mark인 사람을 찾아서 결과를 만드는데, 그중 70%는 내 친구 혹은 친구의 친구 중에서 찾으라는 것이다. 다르게 말하면, 나머지 30%는 나의 소셜 관계망과 관계없이 그 개체의 속성에 따라 “정적”으로 검색한 결과에 할당하라는 뜻이고, 여기에 인기많은 유명인이 들어갈 여지가 생긴다. 이 연산자를 활용하여, 페이스북 직원이 좋아한 레스토랑 찾는 검색을 아래와 같이 소셜하고 맥락있게(social and contextual) 바꿀 수도 있다.
(weak-and
(and place-kind:273819889375819
(or liked-by:fbid1 liked-by:fbid2 ... liked-by:fbidn)
)
(strong-or
(or liked-by:11 liked-by:12 liked-by:20) [0.4]
(or location:palo-alto) [0.7]
) [0.6]
)
내가 현재 팔로 알토에 있고, 나의 친구가 11, 12, 20이라고 했을 때, 검색 결과의 60%는 나 또는 내 친구가 좋아했거나 팔로 알토에 있는 레스토랑이 나오도록 하는 것이다.
여기까지 페이스북에서 공개한 그래프 검색의 내부를 간단히 훑어보았다. 정말 놀라운 무엇이라기보다는 가만히 따져보면 그렇게 하는 게 쉽고 당연하겠다는 방식으로 구현하고 있음을 알 수 있다. 물론 엄청나게 거대한 데이터에 이런 검색 모델이 안정적으로 돌도록 개발하는 것은 그 자체로 대단하고 어려운 일이다. 다만, 개인적으로 기대하는 새롭운 이론 모델은 아직 안 보인다는 얘기다. 생각해보면 페이스북 입장에서는 정교한 알고리즘을 만드는 것보다는 사람들이 정말로 이런 방식의 검색을 원하고 사용할지 여부에 관심이 클 것이다. 지난 10년이 넘는 기간 동안 키워드 기반 검색에 익숙해져 있는 사람들의 스타일을 바꿀 수 있을지, 이런 검색이 정말 쓸만하고 가치가 있을지, 공개했을 때 미리 예상치 못한 문제점은 없을지 등등이 가장 궁금하지 않았을까? 그런 점에서 볼 때 기본 기능을 빠르게 개발해서 공개하고 사용자로부터 피드백을 받아 점차 개선해나가는 전략이 역시나 합당해 보인다.
마지막으로 검색 랭킹에 기계학습을 적용하는 문제에 대한 원저자의 견해를 소개한다.
Although machine learning frameworks can use many thousands of features, we have decided to limit the number of features and engineer these features well. We use machine learning frameworks that combine features in a simple manner – as a linear weighted combination of the feature values. This allows us to keep the scoring formula understandable and we are able to make manual tweaks to the trained formulae as necessary. (기계학습 프레임워크에서는 수천 개의 피처를 사용할 수 있지만, 우리는 피처의 개수를 제한하고 이를 잘 운영하기로 결정했습니다. 기계학습 프레임워크를 이용해서 피처들을 단순하게 결합하는데, 바로 피처값에 각기 다른 가중치를 두고 선형으로 결합하는 것입니다. 이것은 기계학습 결과로 나온 점수 계산 수식을 이해가능하게 유지하고, 우리가 필요할 때 직접 손으로 조정할 수 있습니다.)