스포일러 방지를 위한 연구
정보와 광고의 경계가 모호한 지점이 있듯이 뉴스와 스포일러의 경계도 모호해지는 지점이 생기는 것 같다. (여기서 말하는 스포일러는 공중파 방송 전의 내용 유출이 아니라 방송 후에 인터넷 등을 통해서 결말을 알게 되는 것만을 뜻한다.) “나는 가수다” 같은 서바이벌 프로그램의 탈락자가 누구인지는 방송사에서도 철저하게 보안을 지키려 하고, 시청자 입장에서도 결과를 알고 보면 아무래도 긴장감이 떨어질 수밖에 없다. 모두가 본방사수를 한다면 문제가 없겠지만 VOD가 활성화된 요즘엔 방송이 끝났다고 모두가 이미 시청했다고 가정하긴 어렵다. 그렇다고 아직 안 본 사람이 있으니 방송에 나온 내용을 인터넷에서 얘기하지 말라고 강요할 수도 없고, 해봤자 씨알도 안 먹힌다. 하지만 또 스포일러 피하자고 인터넷을 안 할 수도 없는 노릇. 결국 스포일러의 정의와 경계로까지 논란이 이어진다. 이런 문제를 막기 위해 미리 연구한 사람들은 없을까?
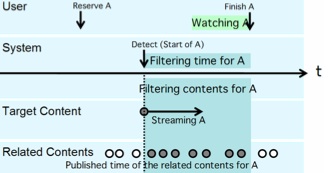
2007년 하와이에서 열린 IUI 컨퍼런스에서 두 일본인 학자는 미리 알면 김이 빠지는 정보를 자동으로 필터링해주는 시스템을 제안했다. 사용자가 즐기려는 TV 프로그램이나 책, 스포츠 경기를 알아낸 뒤, 스포일링이 가능해지는 시점(축구 경기라면 경기 시작 시각, 책이라면 책 출판일)부터 사용자가 결과를 알게 될 때까지는 그와 관련된 정보를 통째로 필터링해버리겠다는 아이디어다.
Temporal Filtering System to Reduce the Risk of Spoiling a User’s Enjoyment. 제목에 ‘시스템’이 들어간 논문답게 현재 사용자가 누구이며, 어떤 컨텐츠를 보려고 하는지, 다 봤는지는 어떻게 체크할지를 길게 얘기하고, 정작 스포일러 컨텐츠를 감지하는 방법에 가서는 단순한 단어 패턴 매칭 방법을 들고 나온다.
축구 경기라면, 리그와 선수 이름 등의 데이터베이스를 따로 마련하고, 또 휴리스틱으로 관련 단어(e.g. ‘골’, ‘승리’)를 들고 있다가 이런 게 포함된 내용은 무조건 필터링해버리자는 것이다. 사용자가 경기를 즐길 때까지 잠시만 미뤄두는 일시적인 필터링이기 때문에 이런 무지막지한 방법도 괜찮을 수는 있겠지만, 그래도 내가 기대한 건 이보다는 조금 더 똑똑한 방법이다.
Coling 2010에 나온 Finding the Storyteller: Automatic Spoiler Tagging using Linguistic Cues이라는 논문에서는 LDA를 써서 영화 리뷰(코멘트)에 스포일러가 담겨 있는지를 검출하는 방식을 제시했다. 영화는 시놉시스가 있으니까 커멘트와의 유사도를 계산함으로써 스포일러성을 판단할 수 있다는 얘기인데, 여기에 LDA 같은 주제 모델(Topic Model)을 쓰면 꼭 동일한 단어가 나오지 않더라도 내용상 유사함을 발견할 수 있다.
하지만, 생각해보면 스포일러라는 건 보통 결정적인 한 문장 한 구절에서 나온다. “범인은 누구다” 이런 식. 그래서 이 연구에서는 단순히 개별 단어를 추출해서 쓰는 것에서 더 나아가, 문장을 문법적으로 분석한 결과를 써서 성능을 개선했음을 강조한다. 예를 들면, “최후의 생존자 김철수” 같은 명사구가 있을 때, “생존자”, “김철수”를 분리하는 대신 “생존자-김철수” 이런 식으로 파싱한 결과도 하나의 단어로 사용했다고 한다.
그러나 이 방식도 시놉시스가 이미 주어져 있는 영화에는 통할지 몰라도 ‘나가수’ 스포일러(?)를 막을 수 있을 것 같지는 않다. 결국 ‘나가수’, ‘탈락’, “꼴찌’, ‘7위’, 그리고 출연자 이름으로 패턴 매칭하는 게 장땡인가?