문서의 품질을 자동으로 측정할 수 있을까?
검색을 할 때 질의어(Query)와 문서 사이의 유사도(Similarity) 못지않게 중요한 것이 문서의 절대적인 품질(Quality)입니다. “흥부와 놀부”로 검색했는데, “흥부와 놀부는 흥부와 놀부는 흥부와 놀부는…” 이런 문서가 나온다고 생각해보세요. 어떤 기분이 들까요?
사람이 쓴 글의 품질을 자동으로 평가하는 일이 그리 쉬워 보이지는 않습니다. 이럴 때는 거인의 어깨에 올라서 봐야죠. 논문을 뒤져보니 위키피디아에 올라온 글을 대상으로 품질을 평가하려는 연구들이 좀 보입니다. 위키피디아는 잘 알려진 것처럼 현재까지 가장 성공적인 위키이며, 모든 글에 대해서 누가 어떻게 편집했는지 기록이 남아 있습니다. 2007년에 출판된 On Improving Wikipedia Search using Article Quality를 보면, 각 글을 완성하는 데 기여한 사람(contributor, 내용을 작성한 사람과 리뷰한 사람 모두 포함)의 권위를 통해서 글의 품질을 측정하려고 합니다. 높은 품질의 글에 기여할수록 그 사람의 권위 또한 높아지는 순환구조의 HITS 알고리즘입니다.
Assessing Information Quality of a Community-based Encyclopedia (2005년) 논문에서는 아래와 같은 문서 특징을 분석해서 자동으로 품질 높은 문서를 찾으려고 시도합니다. 위키피디아의 Featured Article을 품질 높은 문서로 보고 기계학습 기법을 써서 이런 글을 분류해 내겠다는 거죠.

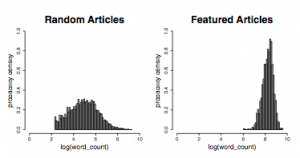 이런 복잡한 모델 말고 그냥
이런 복잡한 모델 말고 그냥 글이 길면 장땡 글의 길이와 품질 사이의 높은 상관관계를 얘기하는 Size Matters: Word Count as a Measure of Quality on Wikipedia (2008년) 이런 논문도 보이네요. (오른쪽 그림 참조) 하지만, 이건 누가 마음먹고 본문을 수십 번 복사-붙여넣기하면 바로 무력해지는 방식이기 때문에 실제로 쓰기에는 무리가 많습니다. 앞서 얘기한 위키피디아 품질 연구도 위키피디아니까 가능한 얘기지 보통 웹문서에까지 적용할 수는 없습니다.
사람들이 웹에 올린 글의 “품질”을 평가하는 일은 어렵기도 하거니와 또한 무척 조심스러운 일입니다. 논리적이거나 무게 잡는 글은 품질이 좋고, 개인의 일상이나 감정을 적은 글은 품질이 낮은 걸까요? 그건 아닐 겁니다. 연구자 중에도 눈을 돌려서 품질 측정이 아니라 글의 성격에 따른 분류라는 관점으로 접근한 사람들이 있습니다. WWW에 2007년 발표된 Exploring in the Weblog Space by Detecting Informative and Affective Articles가 바로 그건데요, 여기서는 블로그 글을 다음과 같이 두 종류로 구분합니다.
- 감정적(affective): 개인의 일상이나 감정을 공유하는 일기성 글
- 정보성(informative): 저자의 취미나 전공, 비즈니스 같은 특정 주제에 대해 정보를 제공하는 글
물론 경계가 모호한 성격의 글도 있겠지만 그건 분류 작업을 할 때 피할 수 없는 문제이고요, Affective-Informative는 꽤 의미있는 구분인 것 같습니다. 저자들도 검색이나 오피니언 마이닝(Opinion Mining)을 할 때 전처리 과정으로 유용하게 쓸 수 있을 것이라 얘기하네요. 한 가지 궁금한 것은 문서를 분류할 때 어떤 문서 특징(Document Feature)을 썼을까였는데, 그냥 키워드만 추출해서 기계학습 알고리즘을 돌렸다고 합니다. 그것만으로도 의미있는 결과가 나왔다고 하네요. 참고로 중국어 블로그 대상입니다.